Bias Evaluation in Prior Authorization AI: What Rigorous Assessment Actually Requires
.png)

Anterior’s proactive approach to bias mitigation
Anterior’s AI platform processes prior authorization decisions for organizations covering tens of millions of lives. We hold ourselves accountable for making sure the system works fairly across every population it serves.
Although our AI only ever recommends ‘approval’ or ‘escalate to human’ (it never denies care), we refuse to accept even marginally slower approvals for certain patient groups.
Regulators are also reaching the same conclusion: CMS's AI Playbook, NIST SP 1270, and state legislation like California's SB 1120 all establish that health plans deploying AI must demonstrate equitable treatment across patient populations, with continuous bias monitoring becoming a compliance requirement.
Therefore, we run continuous bias detection pipelines against production data, with reports like this one generated periodically to document findings across real patient populations.
This report documents a single run of Anterior's bias detection pipeline across 7,166 prior authorization cases showing no meaningful bias across several protected characteristics.
The team behind this

How to think about bias
The most intuitive bias check is to ask: “do different demographics get approved at different rates?”. This doesn't work in prior authorization as medical-necessity guidelines are designed to treat different populations differently.
Medical-necessity guidelines account for patient-specific factors (e.g., age, treatment history, comorbidities, payer type) so approval rates will differ across populations.
Therefore, when checking our AI systems for bias, we ask: “did the AI system introduce errors at different rates across groups when applying the same guidelines under the same conditions?”.
Choosing the right bias metric for prior authorization reviews
We chose parity with experienced clinicians as our gold standard metric to measure system performance against because:
1. It can be run continuously. Our pipelines flag cases where the AI and a licensed nurse reviewer diverge, producing a real-time signal surfacing emerging disparities.
2. It reflects operational reality. Certain guidelines are mandated specifically for certain patient groups (e.g., Medicaid patients are often subject to stricter step-therapy requirements before a requested treatment is approved — which means approval rates will legitimately differ across populations). Reviewer-agreement parity measures model behavior independently of those guideline-driven differences.
We held our evaluation to the industry standard: confidence interval testing against a pre-specified operational tolerance band. We set that bound at ±5 percentage points, pre-specified before examining results, with a statistical power threshold of 80%. This follows the framework recommended by NIST SP 1270 for bias evaluation in AI systems. Additionally, we performed adjusted analysis with protocol fixed effects and additional demographic variables.
This approach aligns with equivalence and non-inferiority testing principles used in regulated domains, and helps ensure that fairness conclusions are grounded in practical impact rather than conventional p-value thresholds as in significance testing.
How the data was generated
Both the AI platform and an experienced human reviewer receive identical inputs (e.g., the clinical documentation, medical-necessity guideline, and requested service) and then produce independent determinations. Agreements are logged as correct; divergences as errors. These error rates are then compared across demographic groups.
.png)
What the data shows
Across 7,166 human-reviewed cases spanning 27 medical-necessity guidelines, adjusted error-rate differences across sex, age, and socioeconomic status remain under one percentage point, and the 95% confidence interval remains well within our pre-specified threshold for operational significance. Protocol-adjusted analyses confirm the same when controlling for guideline mix and additional demographic groups.
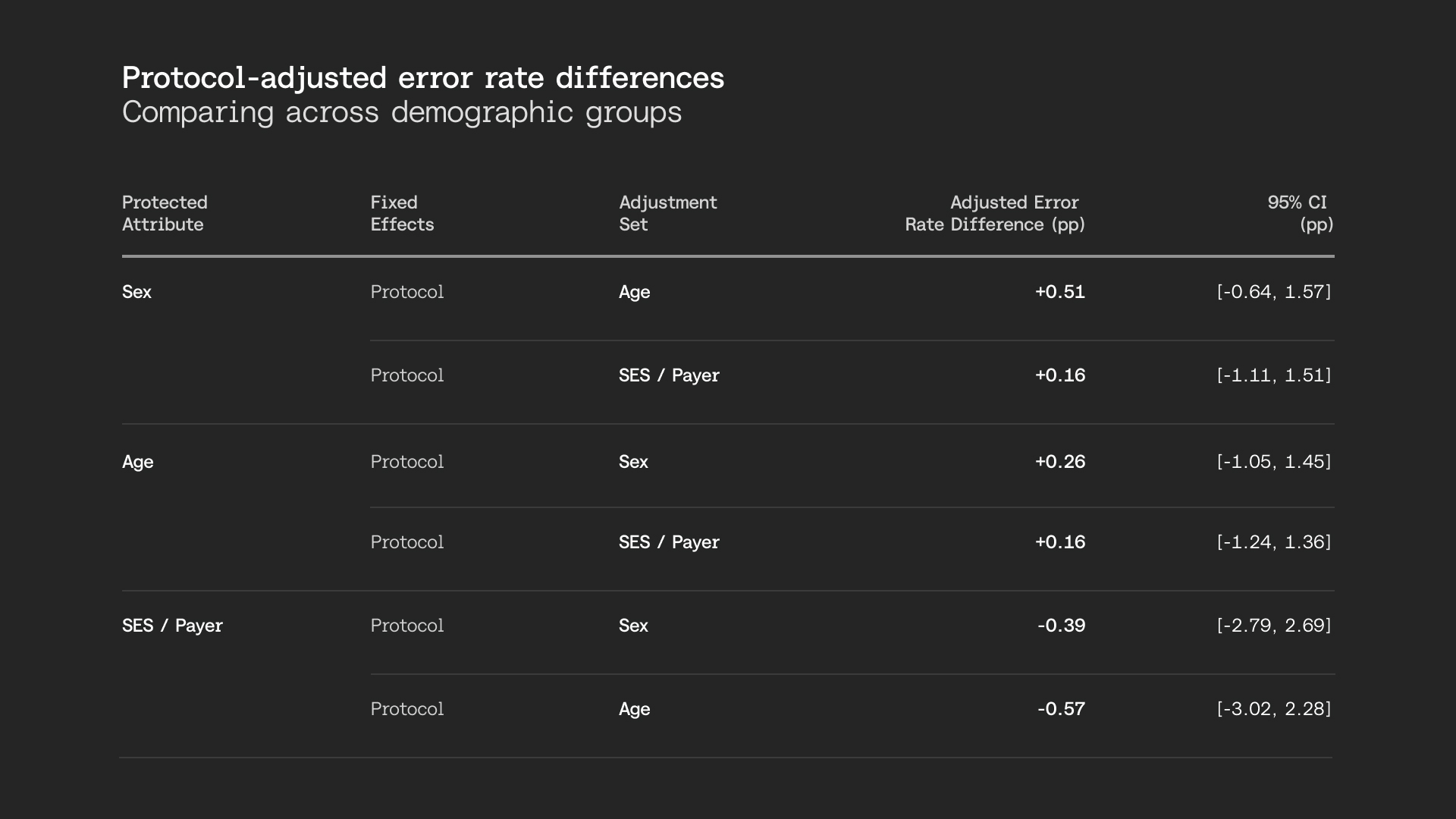
Both unadjusted and adjusted analyses show no operationally significant bias across sex, age, and socioeconomic status. Our system remains consistent whether comparing commercial versus Medicaid patients (a proxy for socioeconomic status), female versus male, or adult versus older adult populations.
Taken together, Anterior's prior authorization AI shows no meaningful bias across demographic groups, a finding that holds consistently across sex, age, and socioeconomic status.
Bias evaluation is an active process
While this report documents a single run of our bias detection pipeline, the pipeline described runs continuously against production data. Batches of cases are evaluated across the same demographic attributes, and results are flagged automatically when they drift outside our pre-specified tolerance bands.

Recommendations for healthcare AI leaders
Anchor fairness evaluation in operational reality. Rigorous bias analysis is one that mirrors how the system actually works in production. That means evaluating against real workflows — not a controlled academic environment that bears little resemblance to daily operations.
As tangible examples, your tolerance thresholds should reflect operational impact (e.g., what magnitude of error-rate difference would actually change member outcomes), your demographic definitions should match what's available in real clinical documentation (not curated research datasets), and your test populations should reflect the case mix your system actually processes. The closer your evaluation is to the real world, the more you can trust what it tells you.
Control for workflow heterogeneity. Different specialties, service lines, or guidelines may have different baseline difficulty or error profiles. Fairness analysis must adjust for this heterogeneity to avoid misleading conclusions.
Maintain an independent validation layer. Both the team and the evaluation methodology used to assess fairness should be independent from those used during system development. When the same people and methods are used to build and certify a system, confirmation bias becomes difficult to avoid.
In practice, this could mean a dedicated fairness review function with its own evaluation protocol, an external audit, or at minimum a documented methodology that is designed and owned separately from model optimization.
Expect fairness evaluation to drift. This is by design. Fairness evaluation should not be a one-off assessment. Instead, it should be continuous, systematic, and have clear signals for reassessment.
A note on race and ethnicity data
Race and ethnicity information was available for only a subset of cases in this analysis, reflecting an industry-wide limitation in administrative healthcare data. With insufficient sample sizes, our pipeline classified these findings as inconclusive — meaning we cannot make claims about parity or disparity for these attributes in this run. We include this as a worked example: responsible bias evaluation requires reporting when the data can't support a conclusion.
Full paper available here.